Chunk 지향 프로그래밍
Chunk란 아이템이 트랜잭션에 commit되는 수를 말한다.
즉, 청크 지향 처리란 한 번에 하나씩 데이터를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk 단위로 트랜잭션을 다루는 것을 의미한다. Chunk 단위로 트랜잭션을 수행하기 때문에, 수행이 실패한 경우 해당 Chunk 만큼만 롤백이 되고, 이전에 커밋된 트랜잭션 범위까지는 반영된다는 것을 의미한다.
Chunk 지향 프로세싱은 1000개의 데이터에 대해 배치 로직을 실행한다고 가정하면, Chunk 단위로 나누지 않았을 경우에는 한개만 실패해도 성공한 999개의 데이터가 롤백된다. Chunk 단위를 10으로 한다면, 작업 중에 다른 Chunk는 영향을 받지 않는다.
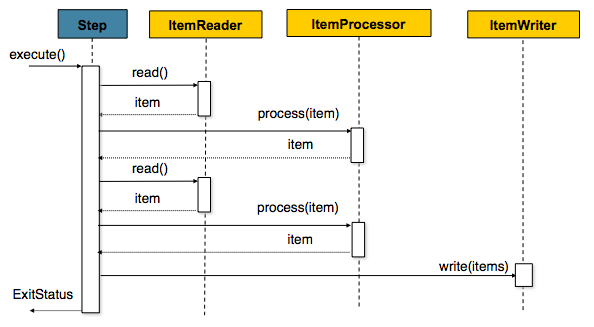
Reader에서 데이터 하나를 읽어 온다.(item 단위)
읽어온 데이터를 Processor에서 가공한다.(item 단위)
가공된 데이터들을 별도의 공간에 모은 뒤 Chunk 단위만큼 쌓이게 되면 Writer에 전달하고 Writer는 일괄 저장한다. (Chunk = items)
여기선 Reader, Processor에서는 1건씩 다뤄지고, Writer에서는 Chunk 단위로 처리된다는 것을 기억하면 된다.
ChunkOrientedTasklet
ChunkOrientedTasklet에서 Chunk 단위로 작업하기 위한 코드는 execute()에 있다.
this.chunkProvider.provide(contribution);: Reaer에서 Chunk 크기만큼 데이터를 가져온다.this.chunkProcessor.process(contribution, inputs);Reader에서 받은 데이터를 가공하고 저장
SimpleChunkProcessor
ChunkProcessor 는 Processor와 Writer의 로직을 구현하고 있다.
ChunkProcessor는 인터페이스이기 때문에 실제 구현체가 있어야하며, 기본적으로 SimpleChunkProcessor가 사용된다.
여기서 Chunk 단위 처리를 담당하는 핵심 로직은 process()에 있다.
Page Size vs Chunk Size
Chunk Size는 한번에 처리될 트랜잭션 단위를 의미하며, Page Size는 한번에 조회할 Item의 양을 의미한다.
AbstractPagingItemReader
현재 읽어올 데이터가 없거나, pageSize를 초과한 경우 doReadPage()를 호출하는 것을 볼 수 있다. 즉, Page 단위로 끊어서 호출하는 것을 볼 수 있다.
Page Size와 Chunk Size를 다르게 설정하는 경우의 예를 들어보자. 만약 PageSize가 10, Chunk Size가 50이라면, ItemReader에서 Page조회가 5번 일어나면 1번의 트랜잭션이 발생하여, Chunk가 처리될 것이다.
한번의 트랜잭션의 처리를 위해 5번의 쿼리 조회가 발생하는 것은 성능샹 이슈가 발생할 수 있다. Spring Batch에서는 다음과 같이 설명이 되어있다.
Setting a fairly large page size and using a commit interval that matches the page size should provide better performance. (상당히 큰 페이지 크기를 설정하고 페이지 크기와 일치하는 커미트 간격을 사용하면 성능이 향상됩니다.)
추가적으로 JPA 사용시에도 lazeException 오류가 발생할 수 있다.
AbstractPagingItemReader를 보면 pageSize의 default 크기는 10인 것을 확인할 수 있다.
그리고 JpaPagingItemReader의 doReadPage()를 보면 this.entityManager.flush(), this.entityManager.clear()로 이전 트랜잭션을 초기화 시키기때문에 만약 Chunk Size가 100, Page Size가 10이라면 마지막 조회를 제외한 9번의 조회결과들의 트랜잭션 세션이 전부 종료되어 오류가 발생하는 것을 볼 수 있다.
이 문제 또한, Page Size와 Chunk Size를 일치시키면 해결되는 것을 볼 수 있다.
2개의 값이 의미하는 바는 다르지만, 여러 이슈로 2개 값을 일치 시키는 것이 보편적으로 좋은 방법이며, 2개 값을 일치 시키는 것을 권장한다.
참고
Last updated