Huffman Coding
허프만 부호화(Huffman coding)는 무손실 압축에 쓰이는 엔트로피 부호화의 일종으로, 데이터 문자의 등장 빈도에 따라서 다른 길이의 부호를 사용하는 알고리즘이다.
압축이란 엄청나게 큰 문제(많은 비트를 필요로 하는)의 정보를 고스란히 표현하면서도 전체 비트량을 줄일 수 있는 효과적인 부호화 기술의 과정이다.
무손실 압축은 데이터 압축의 일종으로 손실 압축의 반대말이다. 원래의 정보를 그대로 보존해야 하기 때문에, 정보 엔트로피의 한계가 그대로 반영된다. 여기에서 정보 엔트로피의 한계란 개별 정보의 확률값에 의하여 계산되는 값이 아닌, 전체 신호의 상관관계를 반영한 한계값이다.
엔트로피 인코딩 or 엔트로피 부호화(entropy encoding) : 심볼이 나올 확률에 따라 심볼을 나타내는 코드의 길이를 달리하는 부호화 방법
엔트로피는 각 기호가 포함하는 평균 정보량을 의미
Shannon 부호화 이론에서는 엔트로피를 우리가 할 수 있는 최선이라 말한다.
자주 발생하는 기호를 찾아내는 데 목적이있다.
가변 길이 부호화(VLC) : 더 자주 발생하는 기호는 더 적은 비트로 부호화
즉, 자주 발생하는 기호는 빨리 전송될 수 있는 코드(적은 비트), 자주 발생하지 않는 것은 긴 코드가 부여된다.
허프만 알고리즘의 부호화 순서는 아래에서 위로 진행하는 방법이다.
알고리즘

초기화 : 모든 기호를 출현 빈도수에 따라 나열한다.
단 한 가지 기호가 남을 때까지 아래 단계를 반복한다.
목록으로부터 가장 빈도가 낮은 것을 2개 고른다.
허프만이 두 가지 기호를 부모 노드를 가지는 부트리를 구성하고 자식 노드르 생성한다.
부모 노드 단 기호들의 빈도수를 더하여 주 노드에 할당하고 목록의 순서에 맞도록 목록에 삽입한다.
목록에서 부모노드에 포함된 기호를 제거한다.
루트노드로부터의 경로에서 각 가지에 코드워드를 부여한다.
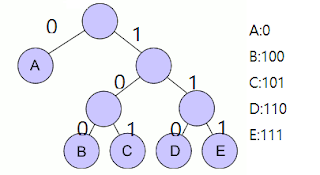
허프만 알고리즘은 입력 기호를 리프 노드로 하는 이진 트리를 만들어서 접두 부호를 만들어 내는 알고리즘이다.
구현
Huffman 알고리즘은 최소빈도 수를 출력하기 위해서 우선 순위 큐를 필요로한다. 최소힙을 사용해서 구현해보았다.
구조체
new_node
Heap 초기화
heapify
두 개의 subtree가 min heap일때 root에 추가된 노드를 포함한 전체가 heap의 조건을 만족하도록 각 노드의 위치를 조정
delete
insert
heap 생성
출력
Huffman 생성
Main
결과
응용
팩스
JPEG
MPEG
Last updated